TitleThe Battle of Recommender System Paradigms: LLM vs. ID
The paper has been accepted by SIGIR 2023.
Title: Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited
Link: https://arxiv.org/abs/2303.13835
Code: https://github.com/westlake-repl/IDvs.MoRec
Research Background
Pure ID Recommender Systems vs. Pure Modality Recommender Systems
Since the advent of matrix factorization, using ID embedding to model item collaborative filtering algorithms has become the most mainstream paradigm in recommender systems, dominating the entire recommendation community for a period of 15 years. Almost all current state-of-the-art (SOTA) recommendation methods use modeling techniques based on ID features. For example, classic two-tower architecture, CTR models, session and sequential recommendation, graph-based recommendation, etc.
However, in recent years, the rapid development of Neural Language Processing (NLP), Computer Vision (CV), and especially the large-scale multi-modal pre-training models has achieved revolutionary results. Large-scale pre-training models (also known as foundation models) have become increasingly influential in modeling and understanding multi-modal (text and image) features. Well-known pre-training models include BERT, GPT, Vision Transformer, CLIP, Llama, etc. With the enhanced ability of the pre-training models to model and understand modal features of items in the recommender system, a natural question arises: can using state-of-the-art modal encoders to represent items replace the classical item ID embedding paradigm? The paper refers to such models as "MoRec." In other words, can MoRec compete with, surpass, or replace IDRec?
In fact, this question was extensively investigated ten years ago. However, at that time, due to the limitations of NLP and CV technologies, IDRec could easily outperform MoRec in terms of efficiency and effectiveness. But does this conclusion still hold today, a decade later? The paper argues that it is necessary to reconsider this question. One important reason is that the classical paradigm based on ID is seriously deviating from the recent advancements in large-scale pre-training model technology. Because IDs cannot be shared across different recommendation platforms, this characteristic makes it difficult for recommendation models to be effectively transferred across platforms, and it is impossible to achieve the "one model for all" paradigm in the NLP and CV fields.
It is worth noting that although many papers in recent years have attempted to introduce NLP and CV pre-training models into recommender systems, these papers often focus on cold start and new item scenarios, where the performance of IDRec is naturally not ideal, as widely accepted. However, for regular scenarios, i.e., non-cold settings and even hot item scenarios, IDRec is still a solid baseline. And in such scenarios, whether MoRec or IDRec is stronger or weaker is still being determined. The paper specifically points out that many existing MoRec papers do not explicitly compare IDRec with MoRec despite claiming to achieve SOTA results. The authors believe that a fair comparison between IDRec and MoRec means at least ensuring the same framework of recommendation models and the same experimental settings (e.g., consistent sampling and loss functions). In other words, other parts should be kept consistent or fair apart from representing items.
The paper argues that a fair comparison between MoRec and IDRec is crucial. If MoRec can beat IDRec even in the hot scenario, the recommender systems may usher in a revolution in the classical paradigm. This viewpoint comes from the fact that MoRec is entirely based on the modal information of items, and such content information inherently has transferability, proving that MoRec has the potential to achieve a universal large model. Therefore, if MoRec can beat IDRec in various scenarios or even achieve a comparable recommendation effect to IDRec, then IDRec may be overthrown. In other words, once the one-for-all recommendation model is achieved, the future recommender systems only need to fine-tune on one or several universal large models or even do zero-shot transfer. If this ideal is reached, the recommendation field will undoubtedly undergo the most significant transformation in nearly ten years, and countless repetitive tasks of recommendation engineers are expected to be liberated.
In addition, the article validates two critical questions: (1) For MoRec, can the progress made in the NLP and CV, i.e., more powerful (multi) modal encoders, directly improve the effectiveness of recommender systems? If this question is answered affirmatively, then the MoRec paradigm undoubtedly has more potential, and as stronger NLP and CV representation models emerge, MoRec will also become stronger. (2) How should item representations generated by NLP and CV pre-training large models, such as BERT and Vision Transformer, be used? The most common practice in the industry is to directly incorporate these representations as offline features into recommendation or CTR models. Is this method optimal? In other words, do the item representations generated by these pre-training models have a certain universality, or must they be re-adapted to recommendation datasets? Finally, the paper presents four challenges for the development of MoRec, most of which have yet to be explicitly addressed in the existing literature.
The paper also points out that thoroughly investigating this issue and even overturning IDRec with just one article is far from sufficient. It will require the collective efforts of the entire recommendation community.
Experimental Settings
Network Architecture
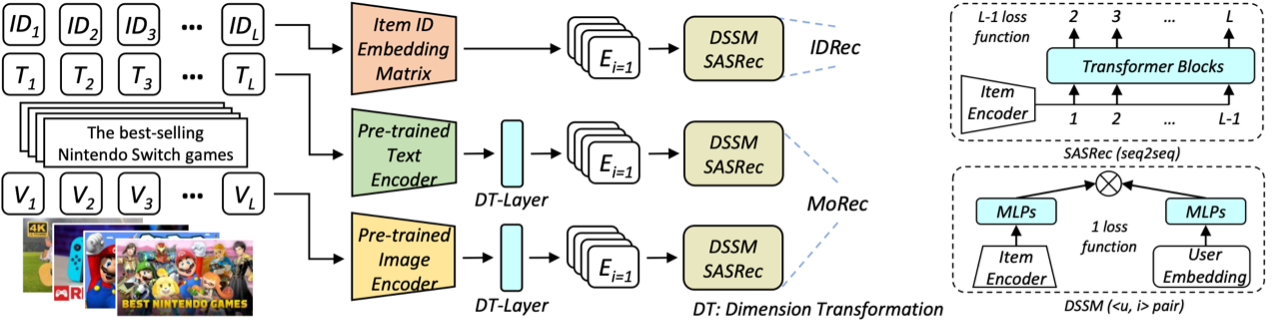
The article evaluated two of the most representative recommendation architectures in the recommendation community to validate the hypothesis. These are the classic two-tower DSSM model (representing the CTR paradigm) and the SASRec model (representing session or sequential-based recommendations). SASRec adopts the popular Transformer architecture.
To ensure a fair comparison, the only difference between MoRec and IDRec is using pre-trained modal encoders to replace the ID embedding vectors in IDRec. Considering that MoRec requires a significantly larger number of parameters under the same recommendation network architecture due to including a massive pre-trained modal encoder network, it is challenging to conduct an exhaustive hyperparameter search for MoRec. Therefore, this paper conducted a broad grid parameter search only for IDRec, located the optimal parameters for IDRec, applied them directly to MoRec, and then performed a simple search in the corresponding smaller tuning space. This tuning approach ensures that IDRec reaches its optimum, but MoRec may not achieve its best performance. Considering the difficulty of parameter tuning, the authors believe that how to tune a MoRec can be an important research direction. The subsequent challenges faced by MoRec further emphasize the significance of hyperparameters for MoRec.
Dataset
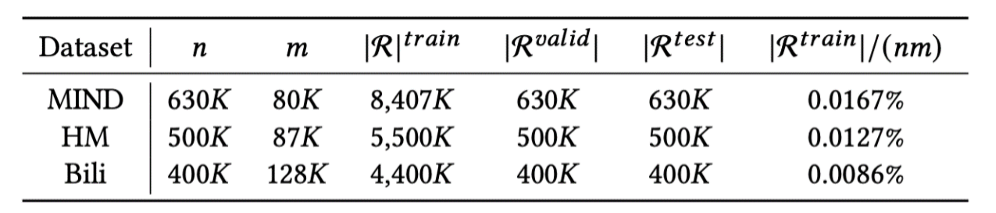
The paper utilized three datasets with user sizes ranging from 400,000 to 600,000 and item sizes ranging from 80,000 to 120,000. These datasets include the MIND dataset, which contains textual information for news recommendation; the HM dataset, which contains image information for e-commerce; and the Bili dataset, which is a video recommendation dataset. All these datasets contain the original modal information of items. MIND and HM are publicly available datasets, and the author has shared the datasets used in the experiments on GitHub. The Bili dataset is derived from an unpublished paper and can be obtained through email; further details can be found on GitHub.

It can be observed that there are certain differences between the images in the Bili and HM datasets and the pre-training dataset (ImageNet) commonly used in CV. Whether the image encoder pre-trained on ImageNet has sufficient generalization ability in the context of recommender systems remains to be discovered. To address this issue, the paper conducts experiments in the subsequent sections.
Experimental Exploration
Question 1: Performance comparison between MoRec and IDRec, especially in regular and hot item scenarios.
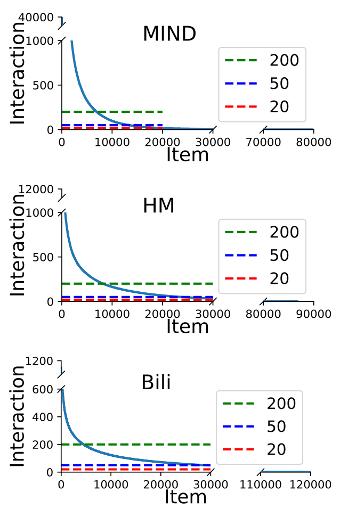
The paper thoroughly compares the performance of MoRec and IDRec in three scenarios: regular, cold-start, and popular item recommendation. The results are as follows:
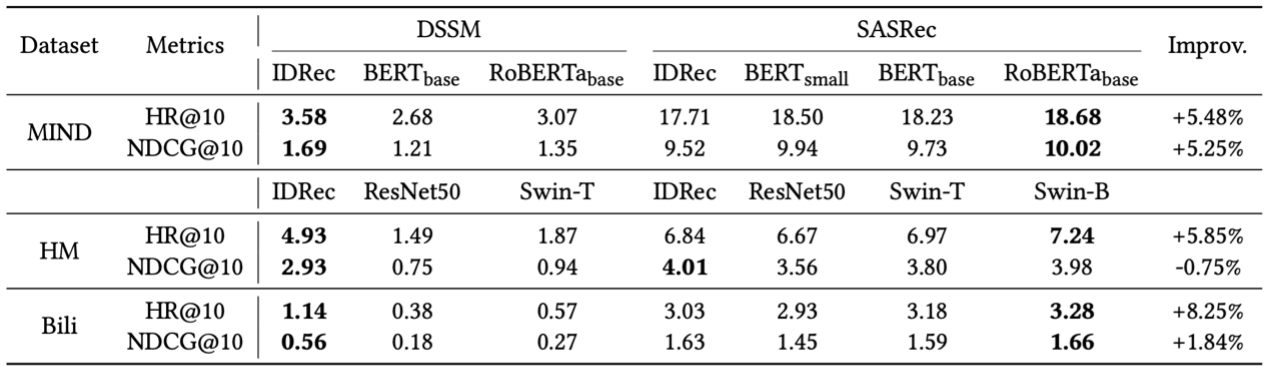
Firstly, in the scenario of regular recommendation, whether IDRec or MoRec, the performance of DSSM is significantly lower than SASRec. This is consistent with many previous studies: representing users using their interaction item sequences is often more effective than treating them as individual user IDs [1, 2]. Meanwhile, there is a considerable performance difference between MoRec and IDRec in both DSSM and SASRec. The paper found that under the DSSM architecture, MoRec's performance is much worse than IDRec across all three datasets. This disparity might lead to a loss of confidence in MoRec, for instance, on the HM and Bili datasets, where IDRec outperforms MoRec by more than twice.
In contrast, under the SASRec architecture, MoRec achieves better results than IDRec on the MIND dataset using any of the three text encoders. On the image datasets Bili and HM, MoRec also achieves comparable results. For example, with the Swin Transformer (base version), MoRec even slightly outperforms IDRec, while with ResNet, MoRec is slightly inferior to IDRec. These comparison results suggest that MoRec requires a strong recommendation backbone (SASRec is superior to DSSM) and training methods (seq2seq is superior to <u, i> pair) to unleash the advantages of modal-based item encoders. On the other hand, the DSSM paradigm struggles to effectively leverage the potential of modal encoders. Given the unsatisfactory results of MoRec in DSSM, the paper primarily focuses on the SASRec architecture in the subsequent analysis.
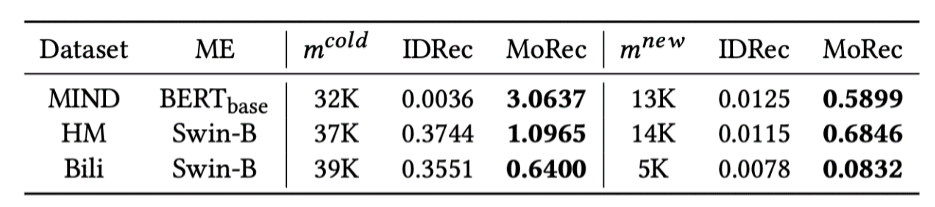
MoRec is naturally suitable for cold-item recommendation because its modal encoders are specifically developed to model the original modal features of items and can represent items regardless of their popularity. MoRec significantly improves over IDRec in cold-start scenarios for text and visual recommendations on all three datasets. This phenomenon aligns with the widespread understanding in the community.
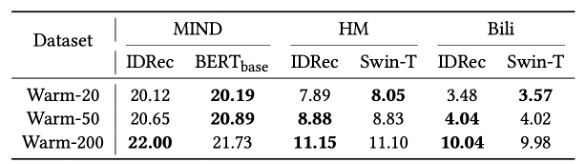
Defeating IDRec is undoubtedly very challenging in recommending popular items, as demonstrated in the paper. By validating with items of different popularity levels, it is found that in moderately popular datasets like warm-20, MoRec can slightly outperform IDRec. However, in highly popular datasets like warm-200 (where all items appear more than 200 times), MoRec performs slightly worse than IDRec in text and visual recommendations. Because IDRec has a significant advantage in modeling popular items [3, 4, 5]. Nevertheless, MoRec can still perform comparably to IDRec even in these hot-start settings.
Conclusion 1: For the SASRec recommendation architecture, in regular scenarios (with both hot and a portion of cold items), MoRec significantly outperforms IDRec in text recommendations and performs comparably in visual recommendations. In cold-start scenarios, MoRec outperforms IDRec significantly, while MoRec and IDRec achieve similar results when recommending popular items. These positive characteristics are attractive, as they suggest that the recommender systems will likely adopt MoRec to replace IDRec. Additionally, considering MoRec's inherent advantages in transfer learning or cross-domain recommendation, once the recommender systems shift from IDRec to MoRec, large MoRec models are likely to become foundational recommendation models similar to ChatGPT [6, 7], thereby achieving the grand goal of "one model fits all recommendation scenarios" [6, 8].
Question 2: Can advancements in NLP and CV technologies simultaneously drive the development of MoRec?
The paper conducts extensive experiments to investigate whether progress in pre-training models in NLP and CV, considering both larger parameter sizes and superior encoders, can simultaneously enhance the accuracy of MoRec recommendations.

As shown in the figure, a larger visual item encoder generally achieves better accuracy in visual recommendations. The results in the text domain are also consistent, with the only difference being that MoRec based on BERT-base is worse than MoRec based on BERT-small, despite the latter having significantly fewer parameters. The conclusion is that larger and more powerful modal encoders from NLP and CV often improve the accuracy of recommendations in general, but this may not strictly apply to all cases.
Simultaneously, the paper explores superior encoder networks. For instance, it is recognized that RoBERTa is outstanding to BERT, and BERT is superior to GPT with similar model scales in most NLP understanding tasks (though not in generation tasks). Swin Transformer is often better than ResNet in many CV tasks. Additionally, these modern pre-training large text models easily surpass famous shallow models developed about a decade ago, such as TexTCNN and GloVe. As shown in the figure, with superior model architectures, the performance changes in MoRec are generally consistent with the research results in NLP and CV.
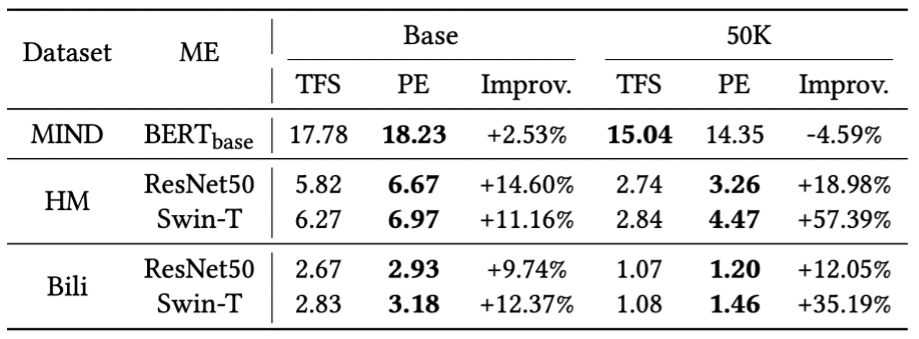
Thirdly, the paper investigates whether modal encoders with pre-trained parameters achieve higher recommendation accuracy than those trained from scratch (i.e., randomly initialized) in the recommendation scenario. The results show that pre-trained MoRec achieves significantly better results on larger and smaller-scale image datasets, consistent with findings in the NLP and CV domains.
Conclusion 2: MoRec establishes a connection between the recommendation and the multi-modality community, such as NLP and CV, and generally inherits the latest advancements in these fields. This implies that once there are future breakthroughs in the respective research areas, MoRec will have more opportunities and significant potential for improvement.
Question 3: Do the representations generated by pre-training models in NLP and CV have sufficient generalization ability for the recommendation scenario? How should we use the representations generated by pre-training models?
An ambitious goal of pre-training large NLP and CV models is to achieve universal text or visual representations that can be directly used in downstream tasks in a zero-shot setting. However, these pre-training encoders are only evaluated on some traditional NLP and CV tasks, such as text and image classification. This paper argues that predicting user preferences in the recommendation scenario is more challenging than the downstream tasks in NLP and CV.
The paper explores two MoRec paradigms:
- Two-stage: Pre-extract modal features with modal encoders offline and then incorporate them into the recommendation model. The two-stage manner is trendy in the industry since real-world recommender systems often involve millions or even tens of millions of items.
- End-to-end: Simultaneously optimize user and item encoders in an end-to-end manner (all experiments reported in the paper are based on the End-to-end manner). This approach involves re-adapting the pre-trained item encoder to the recommendation scenario.
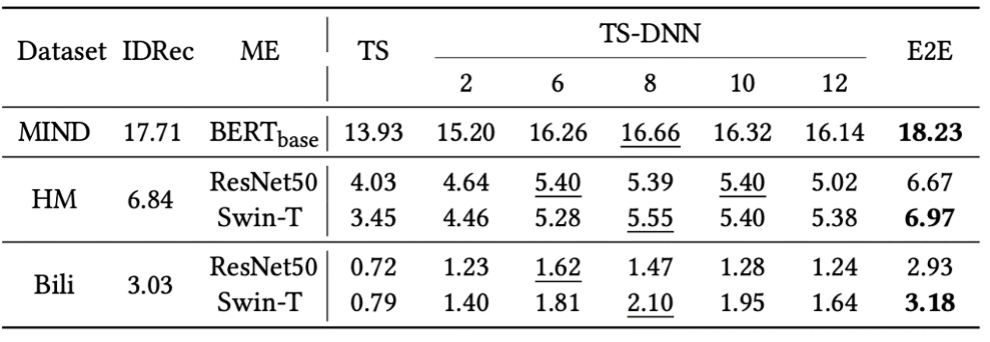
As shown in the table, Two-stage-based MoRec exhibits surprisingly poor results compared to IDRec and End-to-end-based MoRec, with a significant performance gap, especially in visual recommendation where the difference can exceed 50%. The results indicate that the modal representations learned from pre-training tasks in NLP and CV are still not sufficiently general for recommendation problems, and there is a substantial difference in recommendation performance compared to retraining End-to-end.
Conclusion 3: The popular Two-stage offline feature extraction recommendation approach in the industry leads to a significant performance drop for MoRec (especially in visual recommendation), which should be noticed in practice. Furthermore, despite the revolutionary success of pre-training models in the multi-modal domain in recent years, their representations have not yet achieved the required level of generality and generalization, at least for recommender systems.
Key Challenges
E2E-based MoRec has been less studied before, especially for visual recommendation. This paper presents several key challenges and some unexpected findings that the community may not be aware of.
Training Cost
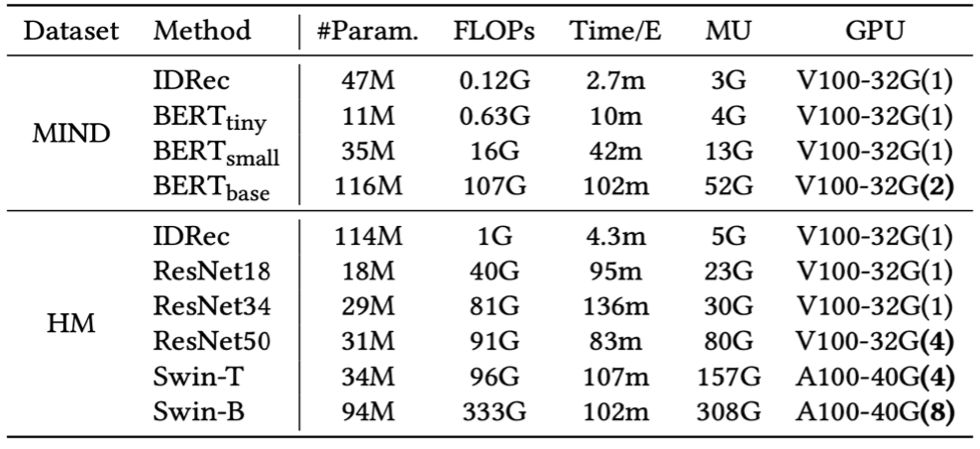
MoRec with larger modal encoders often performs better; however, the compute cost, training time, and GPU memory consumption also increase, especially for seq2seq-based architectures with long interaction sequences. MoRec (using SASRec as the user encoder and Swin-base as the item encoder) requires over 100 times the compute cost and training time compared to IDRec. This might be why previous papers did not combine seq2seq-based user encoders with End-to-end trained modal encoders for MoRec, particularly for visual recommendations.
Additional Pre-training
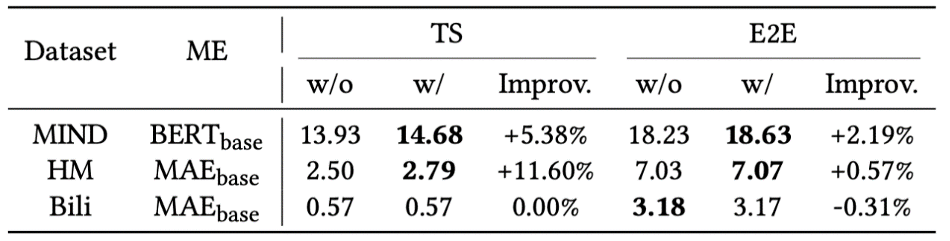
The paper investigates the performance of conducting a second-round pre-training on modal encoders using the downstream recommendation datasets, a technique commonly applied in the NLP and CV. The second-round pre-training will adopt the same strategy as the initial pre-training, such as Masked Language Modeling (MLM). This paper finds that, for text datasets, secondary pre-training improves both Two-stage and End-to-end MoRec. However, for vision, it only enhances Two-stage MoRec in the HM dataset, providing no improvement for End-to-end in HM and MoRec in Bili. The conclusion is that the effectiveness of second-round pre-training depends on individual datasets.
Combining ID and Modal Features

Given that IDRec and End-to-end MoRec perform well, combining these features (i.e., ID and modal) in a single model is a natural idea. The paper evaluates this using two fusion methods: "add" and "concatenate."
Surprisingly, the paper finds that by adding the ID feature, the performance of End-to-end MoRec is even worse than pure IDRec and pure MoRec. This result is somewhat inconsistent with some published papers. One possible reason is that, in a conventional setting, both End-to-end MoRec and IDRec learn user preferences from user-item interaction data, so they cannot complement each other. For Two-stage MoRec, the combination does not improve the results because the ID embedding is much better than the frozen modal features. Another reason could be that more advanced techniques are needed when combining ID and modal features.
In fact, from another perspective, MoRec with ID features will lose many advantages of MoRec. For example, MoRec using ID features is unsuitable for building a fundamental recommendation model because the use of ID features faces challenges related to privacy and the difficulty of overlapping users and items across different platforms.
Model Collapse
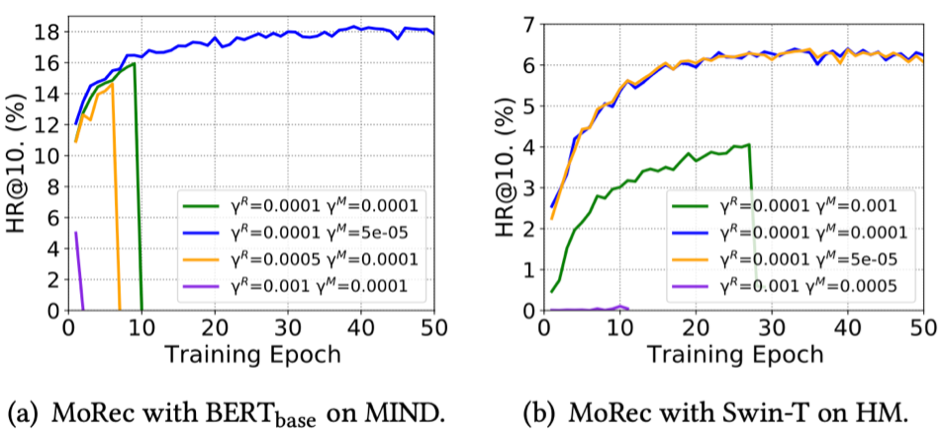
The paper found that training MoRec without proper hyperparameters, especially the learning rate, can easily lead to model collapse. Sometimes, it requires different learning rates for the modal encoder and other modules. One possible reason is that the learning pace of the pre-trained modal encoder should be different from that of other modules trained from scratch.
Conclusion
In summary, the paper investigates an ambitious but under-explored question: whether MoRec has the potential to end the dominance of IDRec in recommender systems. Clearly, this question cannot be fully answered in one paper and requires more research and effort from the RS and even the NLP and CV communities. However, a key finding here is that with the SOTA and E2E-trained modal encoders, modern MoRec can perform as well as or even better than IDRec in typical recommendation architectures (i.e., Transformer backbone), even in non-cold and hot recommendation settings. Moreover, MoRec can primarily benefit from technological advancements in the NLP and CV, suggesting significant performance improvement potential in the future.
This paper aims to inspire more research in the community, such as developing more powerful recommendation architectures, expressive and general modal encoders, better strategies for combining item and user representations, and more effective optimization strategies to reduce computation and time costs. The paper hypothesizes that when modal information of items is available, the mainstream paradigm of recommender systems might have the opportunity to shift from IDRec to MoRec, closely integrating with NLP and CV and mutually promoting development.
The paper claims its limitations: (1) it only considers recommendation scenarios of text and vision, and the effectiveness of MoRec in speech and video scenarios remains unknown; (2) it only considers single-modal scenarios, and the effectiveness in multi-modal scenarios is unknown; (3) the datasets used in the paper are of medium size, and whether the key findings hold when scaled to 100 or 1000 times larger training data (as in real industrial systems) is still unknown.
Reference
[1] Balzs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2015. Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939 (2015).
[2] Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197206.
[3] JiaweiChen,HandeDong,YangQiu,XiangnanHe,XinXin,LiangChen,Guli Lin, and Keping Yang. 2021. Autodebias: Learning to debias for recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2130.
[4] XinyangYi,JiYang,LichanHong,DerekZhiyuanCheng,LukaszHeldt,Aditee Kumthekar, Zhe Zhao, Li Wei, and Ed Chi. 2019. Sampling-bias-corrected neural modeling for large corpus item recommendations. In Proceedings of the 13th ACM Conference on Recommender Systems. 269277.
[5] Fajie Yuan, Guibing Guo, Joemon M Jose, Long Chen, Haitao Yu, and Weinan Zhang. 2016. Lambdafm: learning optimal ranking with factorization machines using lambda surrogates. In Proceedings of the 25th ACM international on confer- ence on information and knowledge management. 227236.
[6] Kyuyong Shin, Hanock Kwak, Kyung-Min Kim, Minkyu Kim, Young-Jin Park, Jisu Jeong, and Seungjae Jung. 2021. One4all user representation for recommender systems in e-commerce. arXiv preprint arXiv:2106.00573 (2021).
[7] KyuyongShin,HanockKwak,Kyung-MinKim,SuYoungKim,andMaxNihlen Ramstrom. 2021. Scaling law for recommendation models: Towards general- purpose user representations. arXiv preprint arXiv:2111.11294 (2021).
[8] JieWang,FajieYuan,MingyueCheng,JoemonMJose,ChenyunYu,BeibeiKong, Zhijin Wang, Bo Hu, and Zang Li. 2022. TransRec: Learning Transferable Recom- mendation from Mixture-of-Modality Feedback. arXiv preprint arXiv:2206.06190 (2022).